May 04, 2015 / by David Wehr / In How-To / 4 commetns
Running CUDA on Google’s Project Tango Tablet
The Google Project Tango tablet is powered by NVIDIA’s Tegra K1 chip, which boasts 192 CUDA cores running Android, perfectly suited for powering a device aimed at cutting-edge computer vision research. Unfortunately, the documentation on taking advantage of this is close to none. I’ll walk you through setting up an Android project that is able to launch CUDA kernels on Tango.

Prerequisites
- Linux 64-bit OS. (NVIDIA officially supports Ubuntu 14.04)
- NVIDIA Tegra Android Development Pack version 3.0r4 (CUDA 6.0)
- Android Studio set up with latest NDK and SDK (I’m using Android Studio 1.2, NDK 10d)
After downloading the Tegra Android Development Pack (TADP) for Linux 64-bit, we must download and install the components we need. The TADP includes its own development environment, with a custom version of Eclipse, but we’re going to set up CUDA with the newly standard Android Studio, which is a far superior IDE, in my opinion. Before the TADP can be run, it must be made executable by right-clicking, going to “Permissions”, and checking “Execute”. Now a double-click will launch it. Be sure to choose a custom install. These are the components we want to install.
- CUDA Toolchain
- CUDA Android Runtime
Now that we have everything needed, we can start coding.
We’ll start by making a new project in Android Studio. I don’t want to make this into an Android tutorial, so I’ll let you make your app. All of the magic for CUDA happens in the Gradle build file and the Android.mk file. Unfortunately, the Android makefile is still needed for us, as complete NDK support has not yet been created for the new Gradle build system.
We need to add building of the C/C++ code automatically. This is described elsewhere on the internet, but I’ll provide a summary here.
Now let’s look at the build.gradle file under “app”. It starts fairly sparse, but we’ll add several things to enable automatic NDK building.
The only changes from default are lines 6 and lines 22-54.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
apply plugin: 'com.android.application'
android {
compileSdkVersion 22
buildToolsVersion "22.0.1"
sourceSets.main.jni.srcDirs = []
defaultConfig {
applicationId "com.davidawehr.cuda_example"
minSdkVersion 19
targetSdkVersion 22
versionCode 1
versionName "1.0"
}
buildTypes {
release {
minifyEnabled false
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
}
}
productFlavors {
armv7 {
ndk {
abiFilter "armeabi-v7a"
}
}
fat
}
task ndkBuild(type: Exec) {
inputs.dir "src/main/jni"
outputs.dir "build/obj"
def ndkDir = plugins.getPlugin('com.android.application').sdkHandler.getNdkFolder()
commandLine "$ndkDir/ndk-build",
'NDK_PROJECT_PATH=build',
'APP_BUILD_SCRIPT=src/main/jni/Android.mk',
'NDK_APPLICATION_MK=src/main/jni/Application.mk'
}
task ndkLibsToJar(type: Zip, dependsOn: 'ndkBuild') {
destinationDir new File(projectDir, 'libs')
baseName 'ndk-libs'
extension 'jar'
from(new File(buildDir, 'libs')) { include '**/*.so' }
into 'lib/'
}
tasks.withType(JavaCompile) {
compileTask -> compileTask.dependsOn ndkLibsToJar
}
}
dependencies {
compile fileTree(dir: 'libs', include: ['*.jar'])
compile 'com.android.support:appcompat-v7:22.0.0'
}
We must add dependsOn attributes to tasks, even the Java compilation one.
By placing dependsOn attributes we ensure that certain tasks don’t run until others have completed.
In the case of compileTask on line 52, that ensures the ndkLibsToJar runs before the Java is compiled.
Also, when declaring the ndkLibsToJar task in line 44, the dependsOn points to ndkBuild, making ndkBuild run before it gets packaged.
In addition, on each task, we note the inputs and outputs, so if nothing has changed, the task will be considered up-to-date, and will not run.
Currently, the first in the dependency chain is ndkBuild. The ndkBuild task launches the ndk-build command, part of the NDK, which is the traditional method for compiling C for Android. The ndk-build will invoke gcc and compile using two new Makefiles, Android.mk, and Application.mk, which we will add later.
Following ndkBuild, ndkLibsTojar will run. This takes the compiled native code, and packages it into a jar that the final apk will contain.
Create a new folder in the project structure under “main”, titled “jni” and create two new files inside: “Android.mk” and “Application.mk”. The jni folder will hold your C source code. Our structure now looks like this:
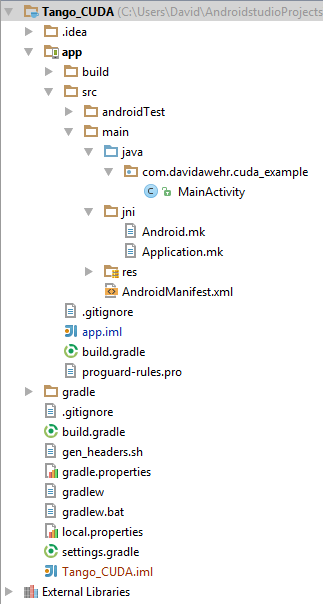
If you build right now, you’ll get an error saying “NDK not configured. That’s because Gradle doesn’t know where we’ve installed the NDK to, so we need to edit the local.properties file, in the top directory, and add a new line that says, for example
1
ndk.dir=/SDK/android-ndk-r10d
Change the path to match where you’ve installed it to. I’ve installed mine to the root in a folder called SDK.
Now let’s look at Application.mk
1
2
3
4
APP_ABI := armeabi-v7a-hard
APP_STL := gnustl_shared
APP_CPPFLAGS := -fexceptions -frtti -fPIC
APP_PLATFORM := android-19
Notes:
- We have to compile for armeabi-v7a-hard, for hardware support of floating points, required for CUDA.
- Setting APP_STL lets us use C++ code
- The application level C++ flags are required for proper CUDA compilation.
- APP_PLATFORM can be whichever you’re targeting, but currently the Project Tango tablet is on Android 4.4 (android-19).
Let’s get some C++ code. First, we have a Java file, JNINative.java for interfacing with the native code. You can place methods in here that will be implemented in C;
I have a method called addArrays, that will add two arrays and return the result.
This file also must load the native libraries that will be compiled later, by calling System.loadLibrary.
1
2
3
4
5
6
7
8
9
10
11
package com.davidawehr.cuda_example;
public class JNINative {
static {
System.loadLibrary("gnustl_shared");
System.loadLibrary("cuda_jni_example");
}
public static native float[] addArrays(float[] a, float[] b);
}
After creating the Java file, recompile the project so it will be made into a .class file. After compiling, we can use javah to automatically create C methods with the correct signature. Here’s the shell script that I use.
1
2
CDIR=$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )
javah -verbose -o $CDIR/app/src/main/jni/jni_native.h -classpath /home/dawehr/Android/Sdk/platforms/android-19/android.jar:$CDIR/app/build/intermediates/classes/armv7/debug com.davidawehr.cuda_example.JNINative
This outputs to a file titled jni_native.h. Here’s what mine looks like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class com_davidawehr_cuda_example_JNINative */
#ifndef _Included_com_davidawehr_cuda_example_JNINative
#define _Included_com_davidawehr_cuda_example_JNINative
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: com_davidawehr_cuda_example_JNINative
* Method: addArrays
* Signature: ([F[F)[F
*/
JNIEXPORT jfloatArray JNICALL Java_com_davidawehr_cuda_1example_JNINative_addArrays
(JNIEnv *, jclass, jfloatArray, jfloatArray);
#ifdef __cplusplus
}
#endif
#endif
Let’s make some more C code now.
native.h
1
2
3
4
#include "jni_native.h"
#include "nativeCUDA.cuh"
float* doAdd(float* a, float* b, int n);
native.cpp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
#include "native.h"
#include "nativeCUDA.cuh"
/*
Place any C++ code you'd like here
*/
float* doAdd(float* a, float* b, int n) {
return CUDA_addVectors(a, b, n);
}
/*
Below this are the JNI implementations
*/
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: com_davidawehr_cuda_example_JNINative
* Method: addArrays
* Signature: ([F[F)[F
*/
JNIEXPORT jfloatArray
JNICALL Java_com_davidawehr_cuda_1example_JNINative_addArrays
(JNIEnv * env, jclass clas, jfloatArray j_a, jfloatArray j_b) {
// Create float arrays from Java arrays
jfloat* a_ptr = env->GetFloatArrayElements(j_a, 0);
jfloat* b_ptr = env->GetFloatArrayElements(j_b, 0);
jint numPts = env->GetArrayLength(j_a);
float* c_ret = doAdd(a_ptr, b_ptr, numPts);
// Set Java array location
jfloatArray j_ret = env->NewFloatArray(numPts);
env->SetFloatArrayRegion(j_ret, 0, numPts, c_ret);
return j_ret;
}
#ifdef __cplusplus
}
#endif
nativeCUDA.cuh
1
2
3
4
5
6
7
8
9
10
11
12
#ifdef __CUDACC__
#define LOG_TAG "tango_jni"
#ifndef LOGI
#define LOGI(...) __android_log_print(ANDROID_LOG_INFO,LOG_TAG,__VA_ARGS__)
#endif
#endif
#define TPB 512
void launchAddKernel(float* d_a, float* d_b, float* d_ret);
float* CUDA_addVectors(float* a, float* b, int n);
nativeCUDA.cu
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
#include "nativeCUDA.cuh"
#include <cuda_runtime.h>
#include <cuda.h>
#define DEBUG
inline
cudaError_t checkCuda(cudaError_t result) {
#if defined(DEBUG) || defined(_DEBUG)
if (result != cudaSuccess) {
LOGI("CUDA Runtime Error: %sn", cudaGetErrorString(result));
}
#endif
return result;
}
__global__ void addKernel(float* d_a, float* d_b, float* d_ret, int n);
void launchAddKernel(float* d_a, float* d_b, float* d_ret, int n) {
addKernel<<<(n + TPB-1) / TPB, TPB>>>(d_a, d_b, d_ret, n);
}
float* CUDA_addVectors(float* a, float* b, int n) {
size_t arr_size = n * sizeof(float);
// Allocate space for sum
float *ret, *d_ret;
checkCuda( cudaMallocHost((void**) &ret, arr_size) ); // Host
checkCuda( cudaMalloc((void**) &d_ret, arr_size) ); // Device
// Allocate device space for a and b
float *d_a, *d_b;
checkCuda (cudaMalloc((void**) &d_a, arr_size) );
checkCuda (cudaMalloc((void**) &d_b, arr_size) );
// Copy a and b to device memory asynchronously
checkCuda( cudaMemcpyAsync(d_a, a, arr_size, cudaMemcpyHostToDevice) );
checkCuda( cudaMemcpyAsync(d_b, b, arr_size, cudaMemcpyHostToDevice) );
// Wait for copies to complete
cudaDeviceSynchronize();
// Launch device kernel
launchAddKernel(d_a, d_b, d_ret, n);
// Wait for kernel to finish
cudaDeviceSynchronize();
// Check for any errors created by kernel
checkCuda(cudaGetLastError());
// Copy back sum array
checkCuda( cudaMemcpy(ret, d_ret, arr_size, cudaMemcpyDeviceToHost) );
// Free allocated memory
cudaFree(d_ret);
cudaFree(d_a);
cudaFree(d_b);
return ret;
}
// GPU kernel
__global__ void addKernel(float* d_a, float* d_b, float* d_ret, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index >= n) {
return;
}
d_ret[index] = d_a[index] + d_b[index];
}
There’s no need for me to explain this, as there exists far better documentation on JNI and CUDA than I can provide. Just note that the .cuh (CUDA header) file cannot include any CUDA-specific code, as it will be included in code compiled by ndk-build, but the .cu file can, since it will be compiled only by nvcc.
Now let’s fill out our Android.mk file to compile this.
Android.mk
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
LOCAL_PATH := $(call my-dir)
include $(CLEAR_VARS)
LOCAL_MODULE := cuda_jni_example
LOCAL_ARM_NEON := true
LOCAL_CFLAGS := -std=c++11 -Werror -fno-short-enums
LOCAL_SRC_FILES := native.cpp
LOCAL_LDLIBS := -llog -lz -L$(SYSROOT)/usr/lib \
-L/home/dawehr/NVPACK/cuda_android/lib -lcudart_static
LOCAL_STATIC_LIBRARIES := libgpuCode_prebuilt
include $(BUILD_SHARED_LIBRARY)
include $(CLEAR_VARS)
LOCAL_MODULE := libgpuCode_prebuilt
LOCAL_SRC_FILES := libgpuCode.a
include $(PREBUILT_STATIC_LIBRARY)
In Android.mk, we see the appearance of cuda_jni_example, the library that we loaded in JNINative.java, as the name of the module to compile. Most of this is standard Android makefile stuff. The notable differences are linking cudart_static library from the downloaded TADP and the libgpuCode_prebuilt module, starting at line 14. libgpuCode_prebuilt takes an archive file called libgpuCode.a and creates it into a module for Android to link with cuda_jni_example module. Where does libgpuCode.a come from?
Back to build.gradle! We have to add automatic compilation of the CUDA code, which we can do by adding a few more tasks.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
task compileCUDA(type: Exec) {
inputs.files "src/main/jni/nativeCUDA.cu",
"src/main/jni/nativeCUDA.cuh"
outputs.file "src/main/jni/gpuCode.o"
def HOME = System.getProperty("user.home")
commandLine "$HOME/NVPACK/cuda-6.0/bin/nvcc",
"-target-cpu-arch", "ARM",
"-include", "/SDK/android-ndk-r10d/platforms/android-19/arch-arm/usr/include/android/log.h",
"-ccbin", "arm-linux-gnueabihf-g++",
"--compiler-options", "\'-fPIC\'",
"-arch=sm_20",
"-m32",
"-c",
"src/main/jni/nativeCUDA.cu",
"-o", "src/main/jni/gpuCode.o"
}
task packageCUDA(type: Exec, dependsOn: 'compileCUDA') {
inputs.file "src/main/jni/gpuCode.o"
outputs.file "src/main/libgpuCode.a"
commandLine "ar",
"rvs",
"src/main/jni/libgpuCode.a",
"src/main/jni/gpuCode.o"
}
compileCUDA is the top-level task, which calls the NVIDIA C Compiler (NVCC), and tells it to compile only, and not link the code. When looking up NVCC command-line options, keep in mind that we’re using CUDA 6.0, as some of these options have been changed in 7.0. Following compilation, we package the .o file into a .a file so ndk-build can make use of it. Don’t forget to add the dependsOn to the ndkBuild task. In the end, our build.gradle file looks like this.
build.gradle
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
apply plugin: 'com.android.application'
android {
compileSdkVersion 22
buildToolsVersion "22.0.1"
sourceSets.main.jni.srcDirs = []
defaultConfig {
applicationId "com.davidawehr.cuda_example"
minSdkVersion 19
targetSdkVersion 22
versionCode 1
versionName "1.0"
}
buildTypes {
release {
minifyEnabled false
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
}
}
productFlavors {
armv7 {
ndk {
abiFilter "armeabi-v7a"
}
}
fat
}
task compileCUDA(type: Exec) {
inputs.files "src/main/jni/nativeCUDA.cu",
"src/main/jni/nativeCUDA.cuh"
outputs.file "src/main/jni/gpuCode.o"
def HOME = System.getProperty("user.home")
commandLine "$HOME/NVPACK/cuda-6.0/bin/nvcc",
"-target-cpu-arch", "ARM",
"-include", "/SDK/android-ndk-r10d/platforms/android-19/arch-arm/usr/include/android/log.h",
"-ccbin", "arm-linux-gnueabihf-g++",
"--compiler-options", "\'-fPIC\'",
"-arch=sm_20",
"-m32",
"-c",
"src/main/jni/nativeCUDA.cu",
"-o", "src/main/jni/gpuCode.o"
}
task packageCUDA(type: Exec, dependsOn: 'compileCUDA') {
inputs.file "src/main/jni/gpuCode.o"
outputs.file "src/main/libgpuCode.a"
commandLine "ar",
"rvs",
"src/main/jni/libgpuCode.a",
"src/main/jni/gpuCode.o"
}
task ndkBuild(type: Exec, dependsOn: 'packageCUDA') {
inputs.dir "src/main/jni"
outputs.dir "build/obj"
def ndkDir = plugins.getPlugin('com.android.application').sdkHandler.getNdkFolder()
commandLine "$ndkDir/ndk-build",
'NDK_PROJECT_PATH=build',
'APP_BUILD_SCRIPT=src/main/jni/Android.mk',
'NDK_APPLICATION_MK=src/main/jni/Application.mk'
}
task ndkLibsToJar(type: Zip, dependsOn: 'ndkBuild') {
destinationDir new File(projectDir, 'libs')
baseName 'ndk-libs'
extension 'jar'
from(new File(buildDir, 'libs')) { include '**/*.so' }
into 'lib/'
}
tasks.withType(JavaCompile) {
compileTask -> compileTask.dependsOn ndkLibsToJar
}
}
dependencies {
compile fileTree(dir: 'libs', include: ['*.jar'])
compile 'com.android.support:appcompat-v7:22.0.0'
}
Now, we should be able to build the application using Android Studio, everything will be packaged properly, and we can run CUDA!
That’s really all there is to it. Once the details are worked out, it’s a straightforward process. The code samples here are integrated into a small demo project that generates random floats and adds them. It’s available on GitHub here. This was developed with my student research at Iowa State University.